词嵌入
语义编码
计算机是很难直接使用人类自然语言的,因此在NLP中的第一步就是将自然语言转换为机器可以看懂、可以处理的数据,即将句子中的每一个词转换为等长的向量,这一步就是嵌入。
嵌入中向量的每一个维度都有潜在的意义,比如说第一个维度代表该词的代表东西的大小,如“金字塔”,该词的对应的嵌入向量第一维度可能就很大,而如“蚂蚁”,该词的第一维度可能就很小。但是这里只是举例说明,在实际情况中,很难暴露维度和语义含义之间的关系。
词嵌入的向量没有一个统一的标准,同一个词在不同的维度下、不同的神经网络下、不同的训练阶段都会有差异。嵌入从随机值开始,通过不断地训练以达到最小化神经网络误差的效果。
将句子中每个单词的嵌入集合到一起,就会得到一个嵌入矩阵。
如这样一句话:
首先,这样一句话会被拆成如下的token:“我”、“喜欢”、“学”、“注意力”、“机制”。之后,其中的每一个token会被编为n维的向量,举个例子,当n=4时,“我”对应的向量是[0.98, 0.05, 0.11, 0.01],这是个行向量,同理,将其余的token转换为向量之后,将其行拼接起来,就得到了一个5x4的嵌入矩阵。
\begin{bmatrix} 0.98 & 0.05 & 0.11 & 0.01 \\ 0.21 & 0.65 & 0.45 & 0.03 \\ 0.15 & 0.91 & 0.20 & 0.08 \\ 0.10 & 0.08 & 0.95 & 0.72 \\ 0.02 & 0.01 & 0.89 & 0.93 \end{bmatrix}这里的每一列的维度都代表了不同的含义,如第一列表示”人“、第二列表示”动作“等。这样就让机器学会了词的含义以及词与词之间的关系。
位置编码
位置编码是一个很关键的问题,词在句子中的不同位置会直接影响到整个句子的含义。如“狗咬人”和“人咬狗”。 在这里Transformer的作者给出了这样一个位置编码
PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{\text{model}}})PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{\text{model}}})pos是词在句子中的位置,i是向量中的维度索引。
该公式为每个位置pos生成了一个d_{model}维的向量。该向量的不同维度i上使用了不同频率的sin/cos波,低频波编码全局位置,高频波编码局部位置,组合起来形成一个独特的位置“指纹”。
关键优势: * 唯一性: 为每个位置生成唯一的编码。 * 确定性: 非学习参数,可预先计算,节省资源。 * 泛化能力: 理论上可以推广到比训练时更长的句子。 * 蕴含相对位置信息: 这是最重要的优点。由于三角函数的周期性,模型可以轻易学习到词与词之间的相对位置关系(例如“前一个词”、“后两个词”),而不是死记硬背绝对位置。
自注意力
第一步,我们将上述例子得到的五个词向量记为a_1,...,a_5,如何去计算每个词之间的关系呢?很简单,只要对这五个向量两两做点积就可以。下面是第一个词与其余词做点积得到权重w_{1n}。
\begin{cases} a_1 \cdot a_1 = w_{11} \\ a_1 \cdot a_2 = w_{12} \\ a_1 \cdot a_3 = w_{13} \\ \vdots \\ a_1 \cdot a_n = w_{1n} \end{cases}第二步,对每个词的所有权重softmax,举个例子:
[w_{11}, w_{12}, w_{13}, w_{14}, w_{15}] \xrightarrow{\operatorname{softmax}} [0.4, 0.2, 0.1, 0.1, 0.2]最后加起来的总和为1,softmax后的结果表示这个词对每个词分配的注意力权重是多少。
第三步,生成新的带有上下文关系的向量编码。
w_{11}a_1 + w_{12}a_2 + w_{13}a_3 + \dots + w_{1n}a_n = y_1这一步中的y_1是“我“这个向量再结合了上下文信息之后的新编码。当我们将这些权重乘以每个词时,我们实际上是在将所有其他词重新加权到第一个词。同理的对其余的向量类似操作,得到蕴含上下文信息的新矩阵Y=[y_1,y_2,y_3,y_4,y_5]^T。
上面三步的所有式子可以表示为
\text{softmax}(A \cdot A^T) = WW \cdot A = Y其中W、Y为
W = \begin{bmatrix} a_1 \\ a_2 \\ a_3\\ a_4 \\ a_5 \end{bmatrix} \begin{bmatrix}a_1,a_2,a_3,a_4,a_5\end{bmatrix}=\begin{bmatrix}w_{11} & w_{12} & w_{13} & w_{14} & w_{15}\\ w_{21} & w_{22} & w_{23} & w_{24} & w_{25}\\ w_{31} & w_{32} & w_{33} & w_{34} & w_{35}\\ w_{41} & w_{42} & w_{43} & w_{44} & w_{45}\\ w_{51} & w_{52} & w_{53} & w_{54} & w_{55}\end{bmatrix}Y = \begin{bmatrix}w_{11} & w_{12} & w_{13} & w_{14} & w_{15}\\ w_{21} & w_{22} & w_{23} & w_{24} & w_{25}\\ w_{31} & w_{32} & w_{33} & w_{34} & w_{35}\\ w_{41} & w_{42} & w_{43} & w_{44} & w_{45}\\ w_{51} & w_{52} & w_{53} & w_{54} & w_{55}\end{bmatrix}\begin{bmatrix} a_1 \\ a_2 \\ a_3\\ a_4 \\ a_5 \end{bmatrix}=\begin{bmatrix} y_1 \\ y_2 \\ y_3\\ y_4 \\ y_5 \end{bmatrix}这里的权重不是训练得到的,并且词的顺序和接近程度是没有关系的,这种为句子添加上下文关系的方法称为自注意力。
SHA 可学习的自注意力 单头自注意力
为了更好的学习上下文关系,我们可以引入可学习的参数。这里引入Q、K、V的思想。
在上面的自注意力公式中,我们发现A出现了三次:
- 第一次 A:作为“查询者”,去和其他词比较。(AA^T 中的第一个A)
- 第二次 A:作为“被查询者”或“标签”,来和其他词比较。(AA^T 中的第二个A)
- 第三次 A:作为“内容的提供者”,被加权求和,形成最终输出。(WA)
我们为这三个A分别起个名字:Query、Key、Value。为了使这三个A有所差异,我们理所应当的引入三个可训练的权重矩阵Q、K、V:
- W^Q (Query 矩阵):它的任务是把原始的 A 转换成一个更适合提问的 Q。
- W^K (Key 矩阵):它的任务是把原始的 A 转换成一个更适合被检索、被匹配的 K。
- W^V (Value 矩阵):它的任务是把原始的 A 转换成一个更适合被提取、被使用的 V。
Q = A W^Q,\quad K = A W^K,\quad V = A W^V这使得模型不再依赖于天生的词之间的关系,而是可以动态的学习更适合用来表示一个词的向量形式。 这使得更新词向量的表达式变为
Y=\operatorname{softmax}(QK^T)\cdot V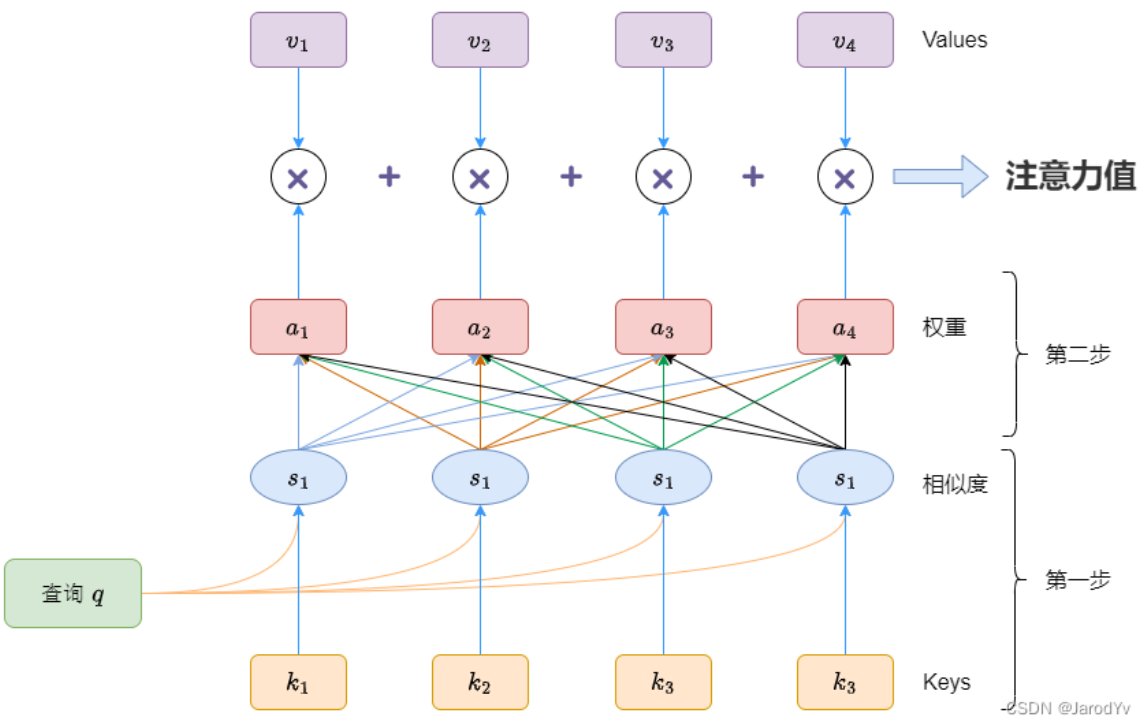
上图为注意力值的主要运算过程,主要为以下几步:
* 首先查询Query和键Key相乘,算出相似度Similarity,即Similarity=QK^T
* 之后乘以权重a,这一步基本上用softmax,即Softmax(QK^T)
* 最后,将上一步的值乘以值Value,即Attention=\operatorname{softmax}(QK^T)\cdot V
在原始论文中,研究人员使用了缩放点积注意力,即
\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V- 为什么要除以
\sqrt{d_k}?- 问题背景:点积
QKᵀ的结果会随着向量维度dₖ的增大而增大。如果维度很大(比如512维),那么点积的结果可能会变得非常大。 - Softmax的“陷阱”:Softmax函数对非常大或非常小的输入值非常敏感。如果输入一个很大的数值,Softmax的输出会趋近于一个“赢家通吃”的分布(比如
[0.001, 0.998, 0.001]),这被称为饱和区。 - 梯度消失:一旦Softmax进入饱和区,它在这些位置的梯度(也就是模型学习的信号)会变得极其微小,几乎为零。这就是梯度消失问题。如果梯度消失了,模型就无法有效地从数据中学习,训练过程就会停滞或失败。
- “缩放”的作用: 除以
\sqrt{d_k}就像一个“音量调节旋钮”。它将点积的数值“拉回”到一个更温和、更合理的范围,防止它们过大。这使得Softmax函数能够工作在一个更健康的区域,从而保证了梯度的有效传播,让整个模型的训练过程更加稳定和可靠。
- 问题背景:点积
掩码注意力
为什么要有掩码注意力? 首先,我们在上述的自注意力中,都是对一句完整的话进行处理,这是没问题的。但是,在我们生活中使用的模型,如GPT、Deepseek,他们都是生成模型,也就是说要根据前文的内容,生成符合前文内容的后文,这就导致了在计算自注意力机制的过程中,他是没有下文的。
我们依旧举个例子,如
在上述自注意力计算过程中,我们在计算“掩码”这个注意力分数的时候,会环顾该句话中的所有词,如前文的“喜欢”、后文的“注意力”。这里会导致一个问题,当机器想要预测“掩码”的下一个词时,它会参考“注意力”这个词的分数,这就相当于拿着答案“注意力”去预测下一个词应该是"注意力",这显然是不合理的。 因此,我们提出掩码注意力,让模型不要偷看“答案”,只根据上文预测下一个词。
\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} +M\right)V其中M为掩码矩阵,是一个上三角矩阵。5阶的掩码矩阵如下所示
M=\begin{bmatrix}0 & -\infty & -\infty & -\infty & -\infty\\ 0 & 0 & -\infty & -\infty & -\infty\\ 0 & 0 & 0 & -\infty & -\infty\\ 0 & 0 & 0 & 0 & -\infty\\ 0 & 0 & 0 & 0 & 0\end{bmatrix}其中-\infty的部分均为下标i>j。
在原有的\frac{QK^T}{\sqrt{d_k}}加上M后,其上三角部分(不包含对角线)都会变成-\infty,经过softmax函数后会变成0,即
\text{softmax}\left(\begin{bmatrix}0.4 & -\infty & -\infty & -\infty & -\infty\\ 0.1 & -0.3 & -\infty & -\infty & -\infty\\ 0.5 & 0.7 & 3 & -\infty & -\infty\\ -1.2 & 1.5 & 0.4 & 0.5 & -\infty\\ 3.2 & 1 & -1 & -0.5 & -2\end{bmatrix}\right)=\begin{bmatrix} 1.00 & 0 & 0 & 0 & 0 \\ 0.60 & 0.40 & 0 & 0 & 0 \\ 0.07 & 0.08 & 0.85 & 0 & 0 \\ 0.04 & 0.57 & 0.19 & 0.21 & 0 \\ 0.86 & 0.10 & 0.01 & 0.02 & 0.01 \end{bmatrix}此时计算出的注意力分数自动屏蔽掉了未来的一些词的影响。
MHA 多头自注意力
前述的均为单头自注意力,多头自注意力机制顾名思义,就是将多个单头自注意力结合起来,这有利于模型从更多角度学到句子中词之间的关系。要注意,多头注意力中词嵌入的向量会平分到每个头中,即如果词嵌入为512维,头有八个,则每个头分到512/8=64维
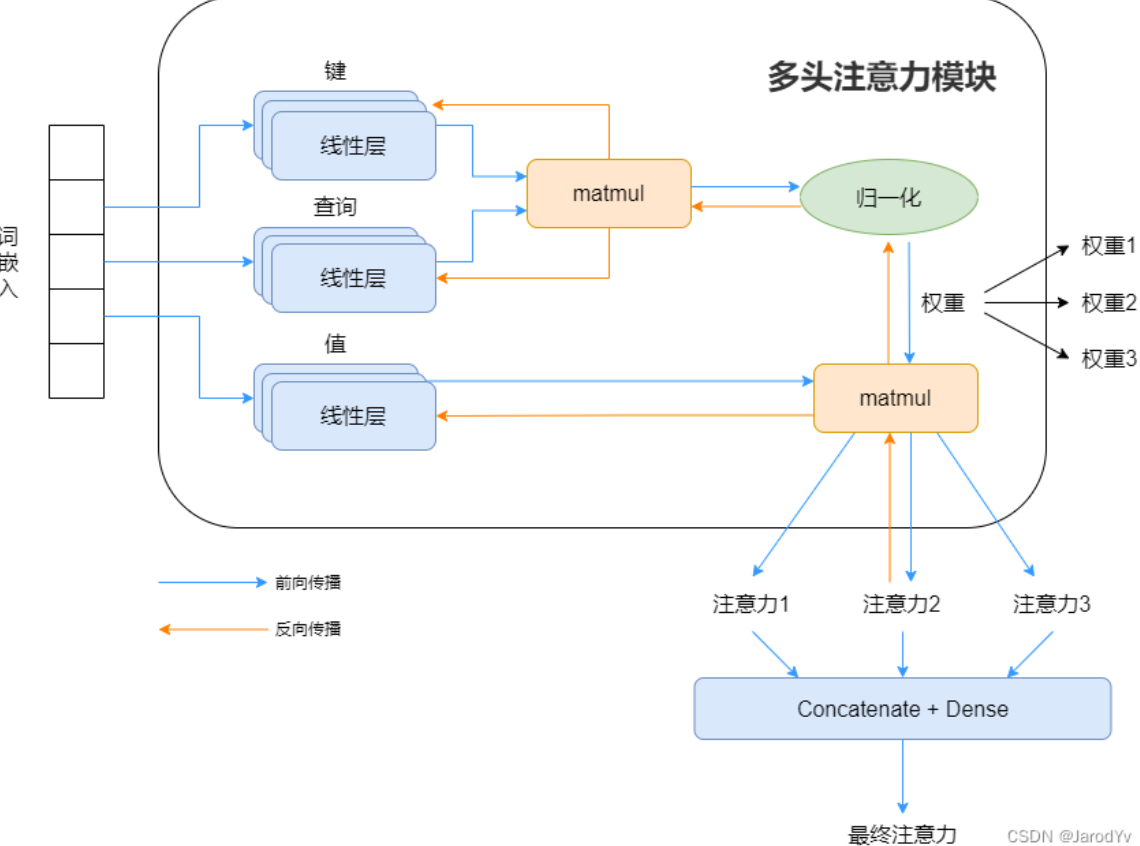
\text{head}_i=\text{Attention}(QW_i^Q,KW_i^K,VW_i^V)\text{MultiHead}=\text{Concat}(\text{head}_1,\text{head}_2...\text{head}_k)W^O其中\text{Concat}为横向拼接,W^O为Concat之后还要通过一层线性层的权重。
参数量问题
这一部分我们来考虑注意力机制中的参数量到底有多少。我们设一个词被编码为n维向量。
先考虑单头注意力机制。
比如拥有一个编码矩阵A = \begin{pmatrix} 0.1 & 0.2 & 0.3 & 0.4 \\ 0.5 & 0.6 & 0.7 & 0.8 \\ 0.9 & 1.0 & 1.1 & 1.2 \end{pmatrix}_{3\times4},这里n=4、三个词。
要使Q = A W^Q,\ K = A W^K,\ V = A W^V的Q,K,V矩阵也为3\times4矩阵,根据矩阵乘法,三个矩阵均为4\times4矩阵,即总的参数量为48。抽象成n,则为3n^2。
加上最后要通过一个线性层的参数W^O,同上的,也为n^2。因此所有参数量为4n^2。
再来考虑多头注意力机制,设头的数量为n_head。一个词被编码为n维向量,以GPT2来举例,n=512,n_head=8,因此,每个头需要处理n/n_{head}=64维信息(输出64维,为的是到最后能拼接成512维的矩阵)。
每个头输入的维数为(token_{num}, n),输出要为(token_{num}, n/n_{head}),则每一个Q,K,V矩阵的维度为(n, n/n_{head}),一共分别有n_head个Q,K,V矩阵,因此总参数量为
n \times \frac{n}{n_{head}} \times n_{head} \times 3 + W^O = 4n^2这与单头注意力机制的总参数量一样! 因此,我们得到这个结论,多头注意力机制的总参数量和单头注意力机制的总参数量相同。
GQA 分组查询注意力机制
分组查询注意力(Grouped-Query Attention,GQA)。 核心思想:把 h 个查询头分成 g 组,每组共享 1 份 K/V 头,但仍保留每份 Q 头独立。
问题提出
MHA每一个Q都有一个独立的KV,这导致训练的时候很占显存;MQA(多查询注意力)是指所有的Q均共享一个KV,虽然没那么占地方了,但是容易导致性能下降。
因此我们提出GQA,这是一个折中的办法,在MHA和GQA之间找一个平衡点,即保留了模型思考的多样性,又极大的降低了显存的占用。
定义
GQA 是一种注意力机制,它保留了多头的 Query(保证精度),但对 Key 和 Value 进行分组共享(减少显存占用和计算量)。
详解
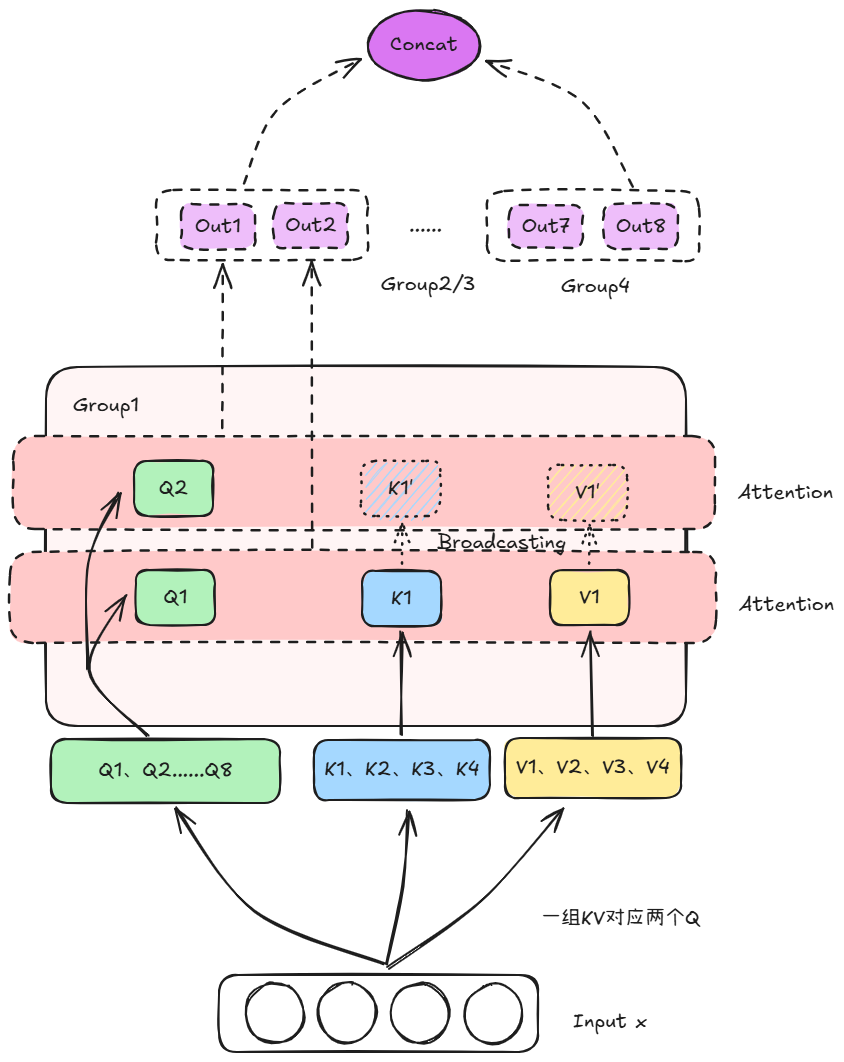
假设我们的配置如下:8个Query头、4个KV头。这意味着每2个Query共享1个KV头。
具体的流程如下:
* 1.输入投影:输入向量 x ,模型生成 8 个 Q 向量(Q_1, ..., Q_8),只生成4 个 K 向量(K_1, ..., K_4)和 4 个 V 向量。
* 2.分组配对:系统自动将他们分为四个小组
* Group 1: Q_1, Q_2 \rightarrow 共用 K_1, V_1
- Group 2: Q_3, Q_4 \rightarrow 共用 K_2, V_2
- Group 3: Q_5, Q_6 \rightarrow 共用 K_3, V_3
- Group 4: Q_7, Q_8 \rightarrow 共用 K_4, V_4
* 计算 Attention
* - 以 Group 1 为例:
- Q_1 与 K_1 计算相似度,得到权重,乘上 V_1。
- Q_2 与 同一个 K_1 计算相似度,乘上 同一个 V_1。
- 虽然用的是同一个 K 和 V,但因为 Q_1 和 Q_2 不同,所以算出来的结果依然是不同的。
* 拼接 Concat
* 把 Q_1 到 Q_8 算出来的 8 个结果拼起来,送往下一层。
GQA的 Attention 公式为,以 Group i 为例
\text{Attention}(Q_{i,j}, K_i, V_i) = \text{Softmax}\left(\frac{Q_{i,j} K_i^T}{\sqrt{d_k}}\right) V_i